

大家都知道,基因带有很多的遗传信息。这张图是大熊猫幼崽刚出生以及出生1-2周之后,我们看到它刚出生时体表是粉红色,并没有出现黑白色,在1-2周之后,它的体表开始慢慢变黑,发育成为与父母比较类似的性状,这其实是基因在父母和子代之间传递遗传信息。
耳垂属于显性遗传,扒王宝强儿子不是王宝强亲生的证据!
儿子和经纪人都有耳垂,王和前妻无耳垂 结论:夫妻双方无耳垂生不出有耳垂的娃,当父母都有耳垂父AA,母AA,则孩子100%有耳垂; 父AA,母Aa,则孩子100%有耳垂; 父Aa,母AA,则孩子100%有耳垂; 父Aa,母Aa,则孩子3/4有耳垂,1/4没耳垂。当父母都没有耳垂,父aa,母aa,则孩子100%没有耳垂。

对于所有生命而言,父母的遗传因素会在孩子的性状包括相貌上如实的反应出来。
这里基因君还是要说一下宝宝的遭遇,如果事关道德底线的事,你不去关心,那其它事也不用关心了,事不关己,高高挂起,从此天下太平。
基因君希望王宝强不要再生活在感性中,理性地对待世界,不是你的孩子,即使再大的感情,也要割裂,因为除了相貌,性格也会遗传。
从以上不管是动物的还是畜牲的遗传中,之所以能得出结论,关键在就在于基因与表达之间的大数据关联,所以基因检测并不是关键,将基因与表达解读出来才是完整的基因检测。在这中间,大数据和云计算起着至关重要的作用,反过来也会促进基因检测的发展。

这是基因检测领域非常经典的一个例子,好莱坞影星安吉丽娜朱莉在2013年查出带有乳腺癌的易感基因,她又结合自己家族的遗传特性,她的祖母和母亲因卵巢癌去世,而姨妈因乳腺癌去世,所以她觉得自己患这些癌症的风险比较高,在医生与自己的商讨决定下,她做了乳腺的切除手术,将自己乳腺癌的风险从87%降到了5%,并且在2015年进一步切除了卵巢和输卵管。这是她的自我保护,当然在医学上会有一些争议,因为这只不过是患病的风险,并不是一种确定性的结果。

我国每年都会有30万例左右带有遗传性缺陷的新生儿出世,同时每年会新增307万肿瘤患者,这是一个比较大的数字。

无论所有的性状表达,包括肿瘤,其实都源于生命本身的中心法则,也就是生命体本质上的一个规律,由DNA转录成为RNA,再由RNA翻译成蛋白质,最后体现在我们的性状上。
肿瘤本身是一种基因类的疾病,也就是说肿瘤的发生就是你体内某些组织里的抑癌基因或致癌基因发生了突变,导致整个细胞的扩增变的不受控,结果就形成了肿瘤组织,这是被公认的肿瘤发病原因。当然,有抑癌基因和致癌基因可能会在不同组织里有不同的位点,也就是说其实肿瘤发病的机制会比较复杂。

这张图其实就描述了中心法则涉及的三个部分,一个是DNA,是一个双链的双螺旋结构;RNA,这个是单链的;另外还有蛋白质,这张图上实际是一条蛋白质的多肽。我们前面说的遗传,肿瘤,都与中心法则有关系。中心法则涉及的DNA、RNA、蛋白质需要通过现代生物技术将整个过程数据化。

如何读取生命的密码—基因

这张图来自艾瑞今年刚发的一份研究报告,很好的整理了整个基因测序发展的脉络。在1953年,沃森和克里克就提出了DNA双螺旋结构, 70年代有了早期的测序,桑格测序法,慢慢在八九十年代,有了这种可以商业化的测序技术。我们真正开始能够对基因做大规模的测序是来自于二代测序的发展,也就是在2005年之后。
二代测序让我们对基因测序有了更大能力。近几年开始有了一些单分子的测序技术,被认为是第三代的测序技术,但目前整个基因测序领域还是以二代测序为主。DNA是一个大分子,它上面有人的全基因组,会有30亿个碱基对。我们可以认为每个碱基对是一个字母,也就是它数字化后可以是ATCG这四个字母中的一个,每个字母的长度非常小,大概只有1-2个埃,而埃是一个长度单位, 相当于头发直径的50万分之一,所以现在的测序技术,希望在这个尺度上面将碱基的信息读取出来。
二代测序技术实际上是将DNA的长链分子随机打断,然后用一些化学的方法去一批批的将它扩增和读取出来。我们可以打个比方,假设我们的DNA分子是一张白纸上面打印的一篇文章,我们就相当于将这篇文章放进了一个碎纸机,变成了一条条小的片段,接着我们就可以基于小的片段将上面的字母读出来,最后我们还需要用生信分析的数据技术将片段拼回成为一个完整的基因组。
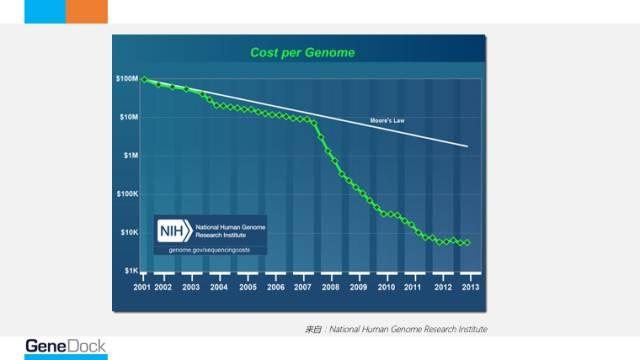
这张图是NHGRI做的非常有名的一张图,它描述的是整个基因测序成本的下降。之前有一个非常大的计划叫做人类基因组计划,实际上是说测出了第一个人类基因组的草图,这个计划一共持续了13年,共耗资4.37亿美元。现在,基于最先进的二代测序技术,已经可以花不到1000美金在一天之内完成一个全基因组的测序。

基因数据的生产应用及产业发展挑战

这张图是现在测序仪的样子,左边是测序仪制造最大的生产商Illumina的测序仪,它最大规格的测序仪是由10台测序仪构成的,型号叫做HiSeq X Ten。有了这套系统,可以在一周之内完成300个个人全基因组的测序。右边是华大基因最新推出的测序仪BGISEQ-500,是国产可供商用的高通量测序仪。
目前在中国有了9套Illumina x ten的测序设施

每年可以完成将近20万人的全基因组测序。每个人的全基因组测序会产生大概100GB的数据量, 20万人的全基因组意味着一年会产生20个PB的数据量,而这个数据的产能还在持续的增长。所以如何更高效的应用和管理这样量级的数据是这个行业的挑战。
现在的二代测序技术相当于用碎纸机将纸碎成小片段,再将小片段拼回来,所以意味着后端对数据的处理需要复杂的流程和算法,以及一个比较大的计算量,所以这也是我们面临的计算上的一个挑战,而云计算正在着力于解决这些问题。

这张图描述的是从测序产生数据,到最后基于这些数据出一份面向终端应用的报告的数据流,人全基因组会产生90G base,将近100GB级别的原始的数据资料。我们需要将这些数据做传输,进一步的进入存储系统做管理、分析、计算,将其中每个人与别人的差异或者自体的差异这些变异位点找出来,基于这些位点结合公开的数据库做注释,最后生成这个位点与疾病或健康因素的关系,基于这些注释的结果,形成一份可读的报告。
临床专家会基于这些信息做进一步的解释,给相应的对象提供临床的指导和治疗方案,到这里,基因检测的整个流程才算基本完成。

从以上,我们可以看出,准确的基因检测只是第一步,从基因检测结果到遗传表达的正确解读才是关键,而在这中间,随着检测样本量的增加,大数据和云计算将会不断的提高解读的可靠性,最终不断趋向于理论上的基因与表达客观完美关联性。
以上部分内容来自于8月16日,联想之星Comet Labs邀请到GeneDock CEO李厦戎作客Comet Talk线上微课时的干货分享
更多文章请关注公众号:基因谷(jiyinguzixun)
基因谷:基因检测领域最新技术进展、最新临床应用、最新行业资讯。
,")
")
")
")
")
")
")
")
")
")
")
")
")